Collection Loader
Summary
Directed the end-to-end creation and launch of a new automated migration tool from initial concept to product rollout. 35+ institutions have utilized this tool to publish 10,000+ items, exceeding adoption goals by over 10% and generating over $60,000 in revenue.
Role
- Design Sprint faciliator
- Concept designer
- Concept Testing facilitator
- Visual designer
- Led scope for Minimal Viable Product (MVP)
Goal
Libraries and cultural institutions with primary source materials want to publish to JSTOR for wider reach, engagement, and impact in the scholarly community, but many institutions lack the time and resources to manually import and publish their existing collections onto a new platform. They need a simple and intuitive method to transfer their data onto JSTOR and manage their presence.
Dashboard
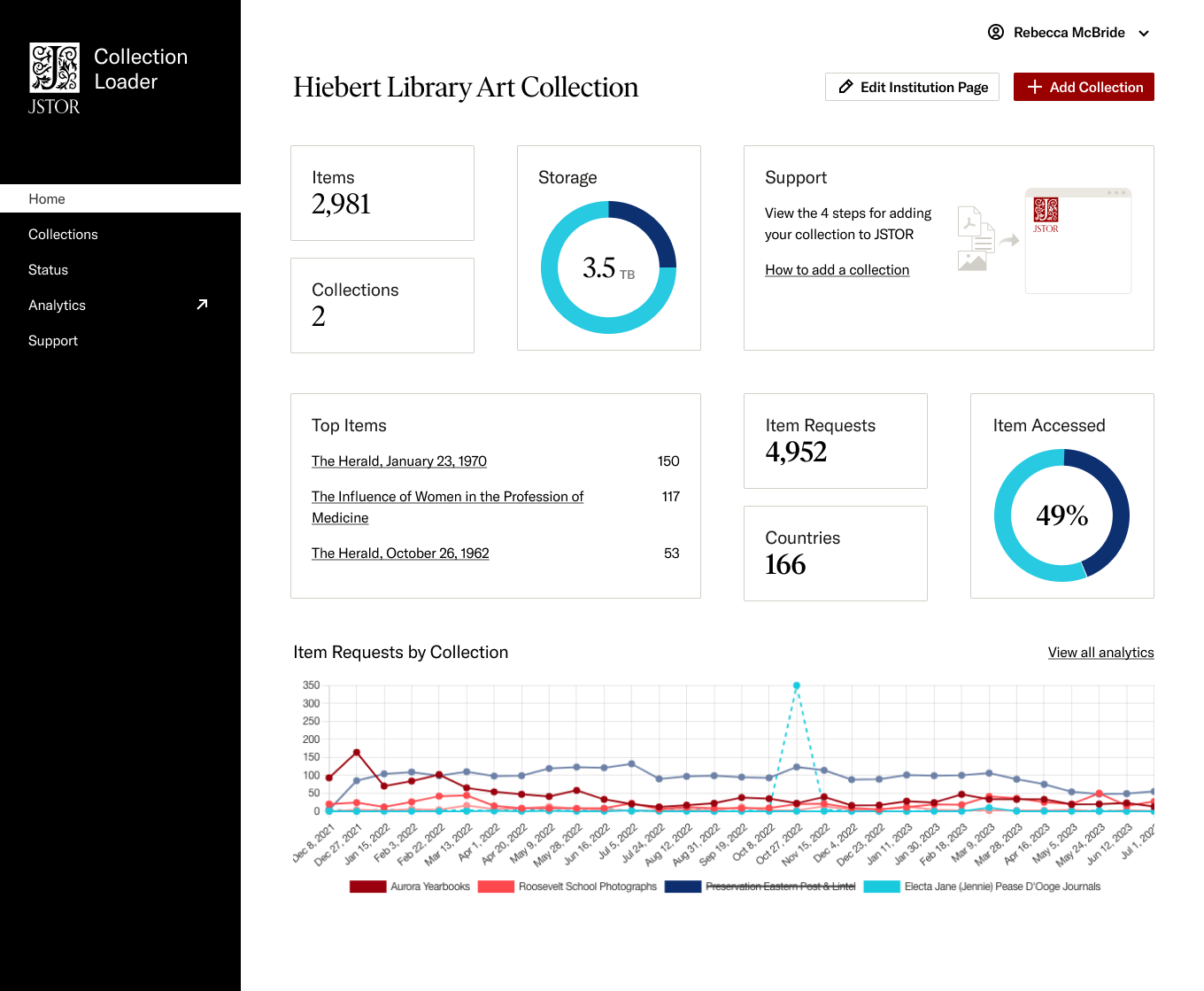
The homepage dashboard provides a high level view of the health of their collections. It is also a starting point for creating new collections.
Video Introduction
Process
- Kicked off with a design sprint focused on problem definition and solution ideation.
- Creating low fidelity screen designs to encourage candid feedback and open the door for spontaneous suggestions.
- Solicited user feedback by having early adopters test a working prototype, aiming to evaluate usability and measure interest in adopting the tool.
- Distilled the key elements from the early adopter phase to make informed judgments and negotiate what constitutes a viable product.
Design Sprint
We kicked off with 3-day design sprint with our core product team of one Product Manager, a Product Designer (myself), a UX Researcher, and four engineers. We consulted relevant experts including a Metadata Librarian, Data Governance Director, Product Marketing Director and VP of Open Collections to inform our direction. The abridged sprint focused on problem definition and solution ideation. We identified key risks, focus areas [*], design principles and created concept sketches [**]. I Synthesized the sprint outputs and developed an initial concept to validate with users.

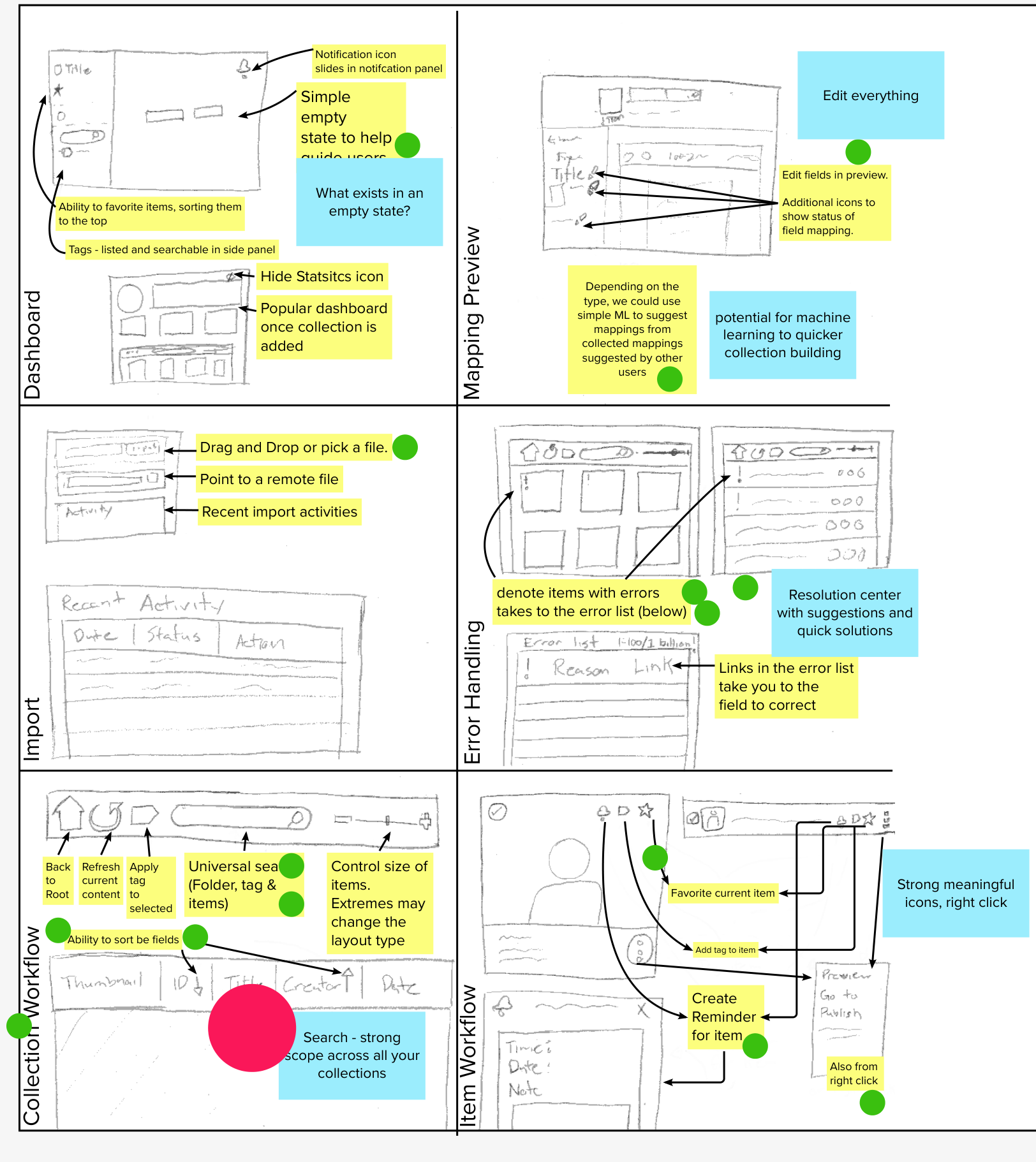
Low Fidelity Concept Testing
We began with low fidelity screen designs to encourage candid feedback and open the door for spontaneous suggestions. This approach prevented participants from assuming the designs were final.
Marketing Email
One of the crucial pieces to test was the marketing email. I needed to provide a realistic preview of what our new product would produce to guage interest. I curated a few collections to include in the ‘concept’ email and iterated on the types of collections we highlighted to show a breadth of examples. This sole screen provided a wealth of evidence and definitive direction.
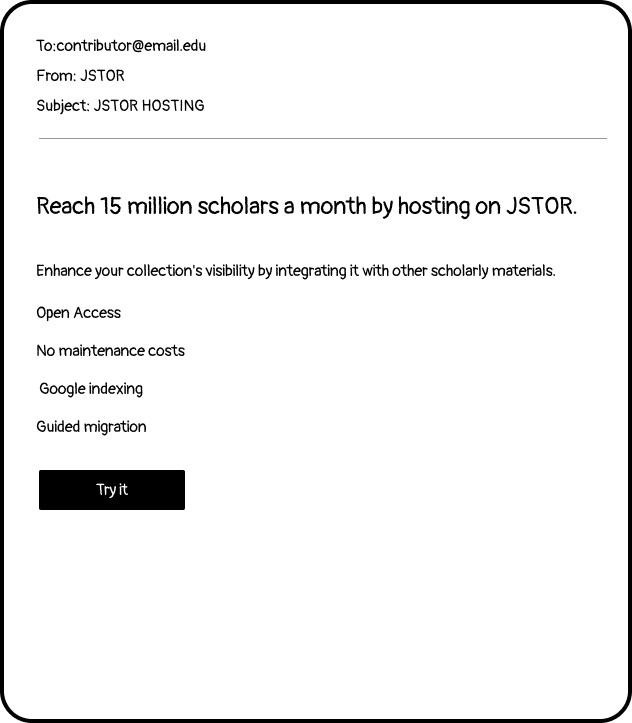
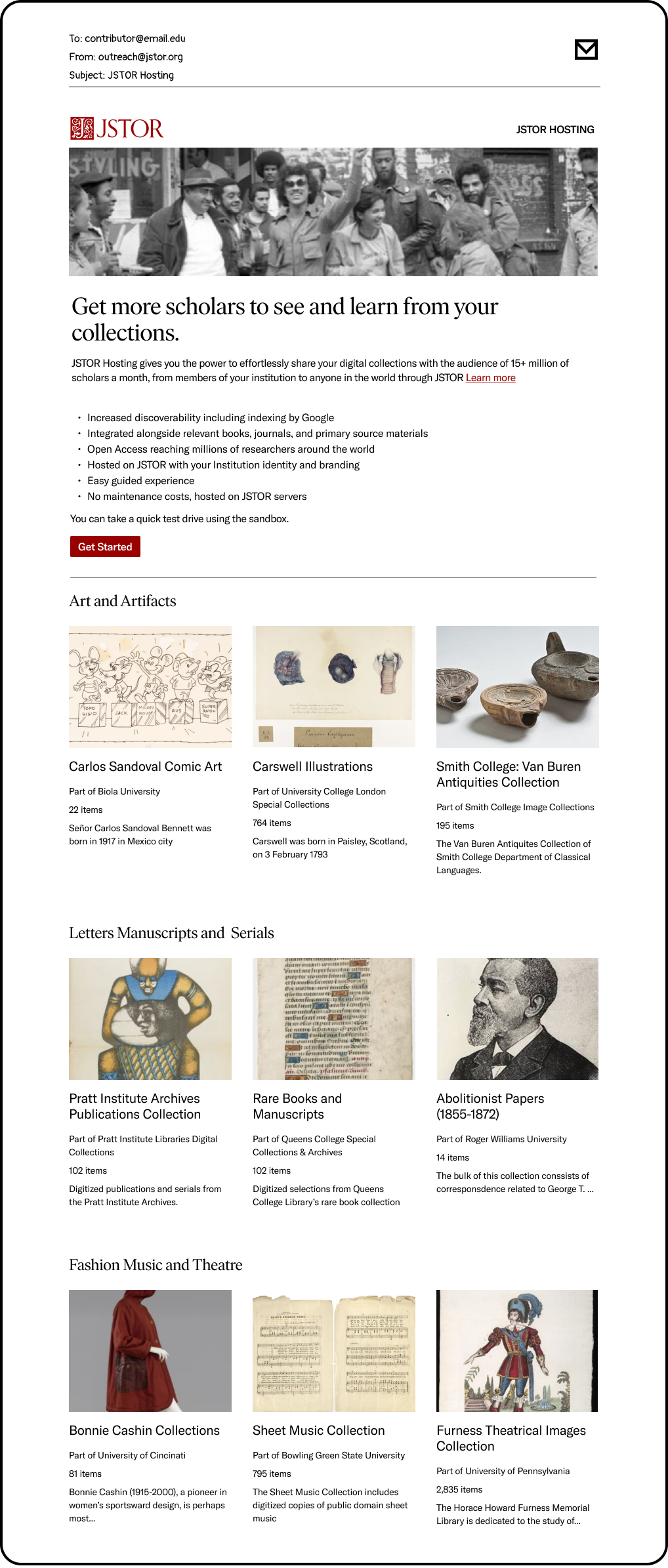
The Starting Point
We needed to understand how potential users wanted to begin using the Collection Loader. Would they prefer starting from the overall structure and themes, or focus instead on the media objects and metadata? To find out, we showed side-by-side options that represented each approach. This comparative format sparked a valuable dialogue about the merits of each and gave us tangible insights into real user preferences. Ultimately, the side-by-side comparative approach was a big win - it enabled us to tease out user needs and make more informed design decisions.


User Control
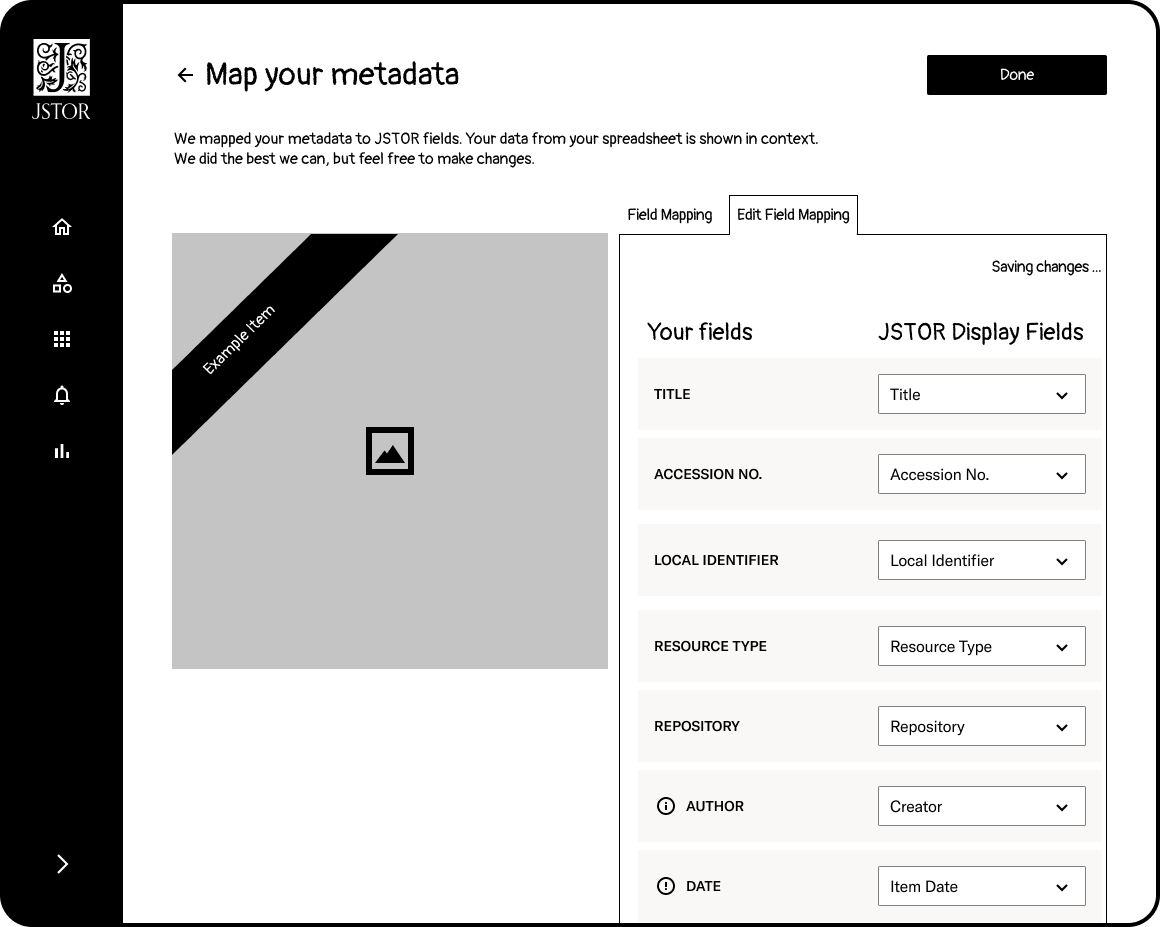
Mapping metadata is arguably one of the most important steps in the publishing process. The system is showing how it interprets the metadata from the user and allows them to make changes.
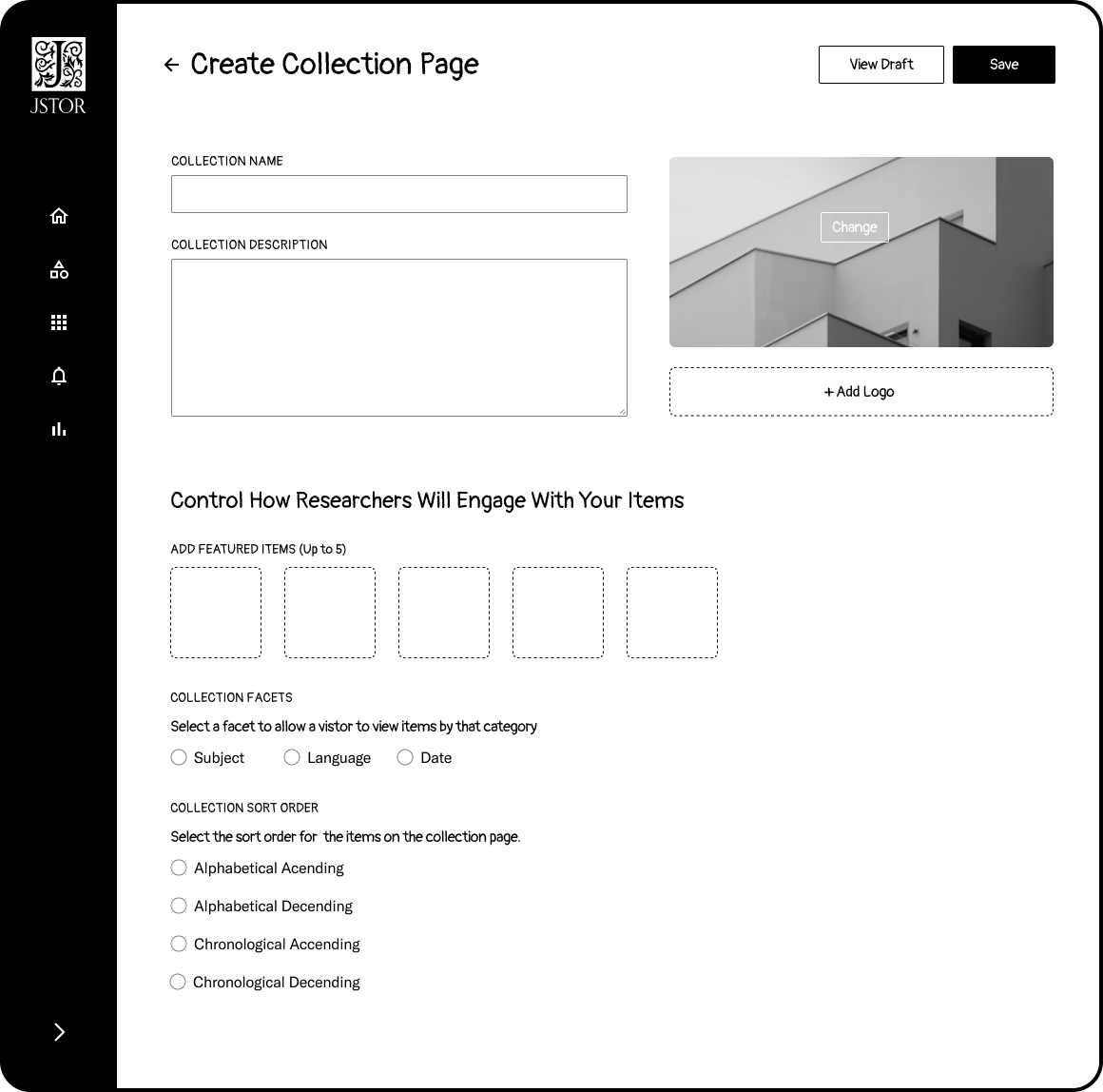
Another crucial step in the process is to set up how the collection will be presented to scholars. Here we explored what types of tools and context they would like to provide a scholar when visiting their collection.
The concept test gave us the confidence we needed to start investing in building something. Next we wanted to test a beta with real metadata from users to get a more realistic view of how valuable users would find the product.
Early Adopter Program
The Collection Loader Early Adopter Program was broken up into 2 phases.
- Phase 1 - the “overview session” where participants met with the team to get an introduction of the Collection Loader, answer any questions, and discuss trialing the tool.
- Phase 2 - the actual hands-on trial of Collection Loader where participants loaded and published a collection to JSTOR.
Goals
Test usability, and gauge interest in the adoption of the tool.
Participants
Twenty five institutions in total participated in Collection Loader overview sessions, while fifteen institutions trialed the Collection Loader tool.
Findings
Despite—and because—the Collection Loader tool being in development throughout this program, participants provided valuable insights that informed product and development priorities.
- Aligned the product design closer to the needs of the user
- Pinpointed critical pre-launch issues for resolution.
- Validated workflow, design, and opportunities for improvement.
- Created an FAQ to equip the support and onboarding teams.
“This process is amazing for us. I used to use CONTENTdm and would set it up to upload overnight. I could do the same [with Collection Loader]— load it at the end of day. This works for us! Donors complain: Why isn’t it up? And here I have control.” —Megan, Southwestern University
Launch Q3 2023
Bridging the Gap Between Catalogers and Scholars
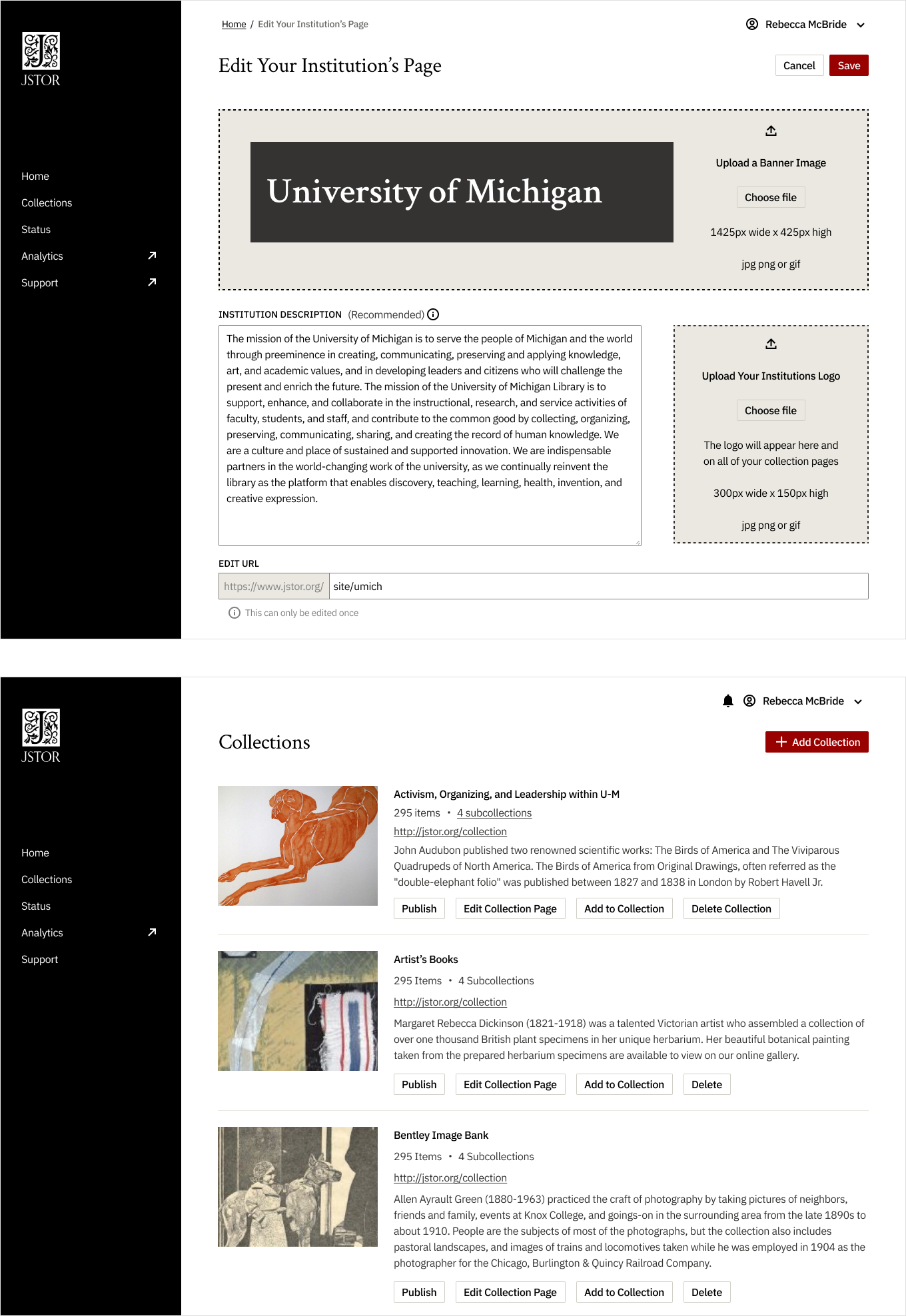
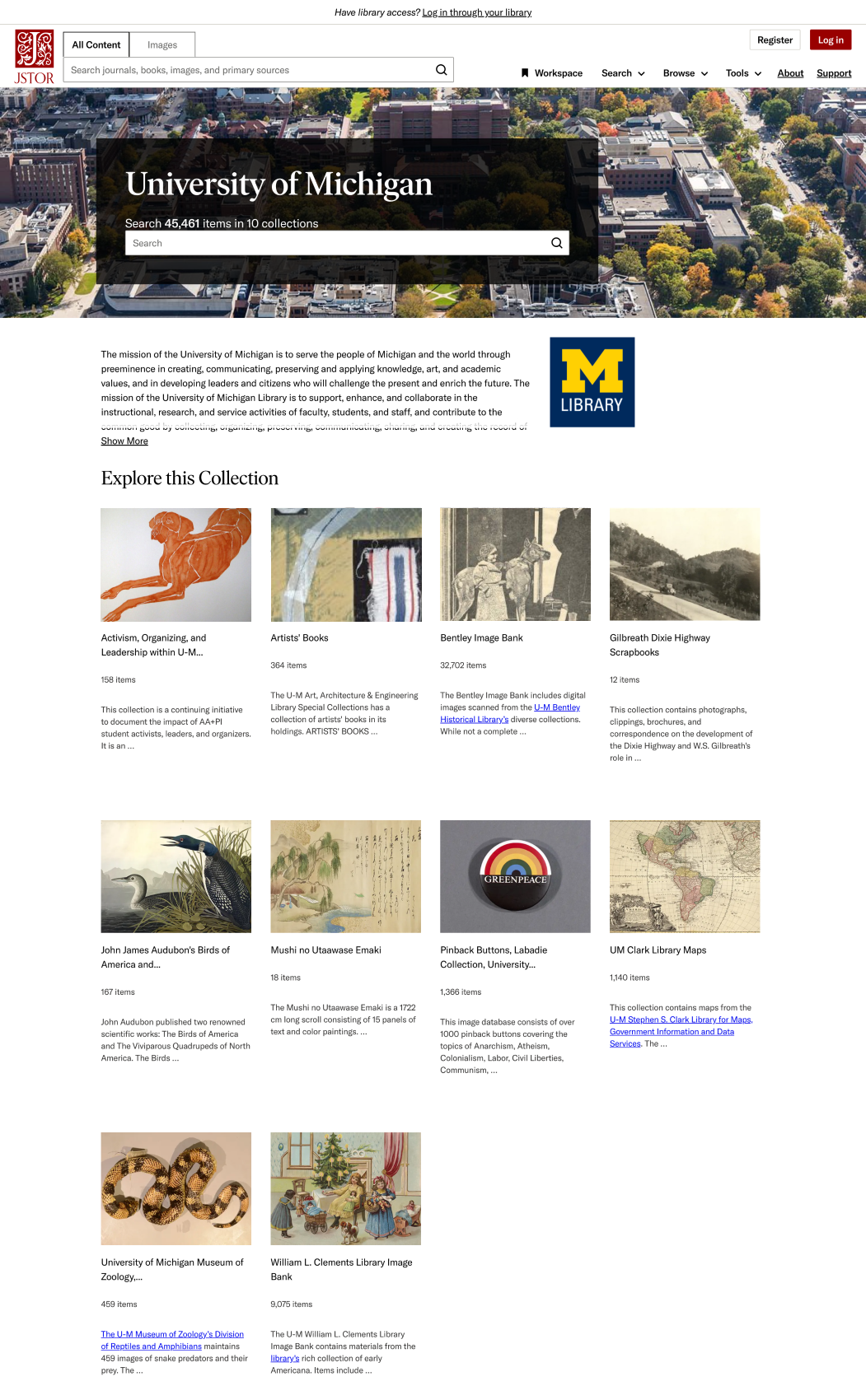
The goal of the collection loader publishing tool for catalogers was to create a seamless experience that aligned with what scholars see on the platform.
Catalogers and scholars both interact with collections, but their perspectives and needs differ significantly. Catalogers manage and curate collections, ensuring their accessibility and discoverability for scholars. Scholars, on the other hand, rely on these collections for research, evaluation, and making new discoveries.
To bridge this gap, we developed a collection list that mimics the scholar's view while providing comprehensive management tools for catalogers. This approach allows catalogers to provide the context and information scholars need to effectively evaluate and utilize the collections.
Through user testing with catalogers, we refined the tool to include the following features
- Alignment: An adaptation of the collection list scholars see on the platform, ensuring consistency and familiarity.
- Management Tools: A comprehensive suite of tools for catalogers to manage, publish, and edit collections effectively.
- Context: Contextual information, such as collection descriptions and related materials, to aid scholars in their evaluation and use of the collections.
Guidance
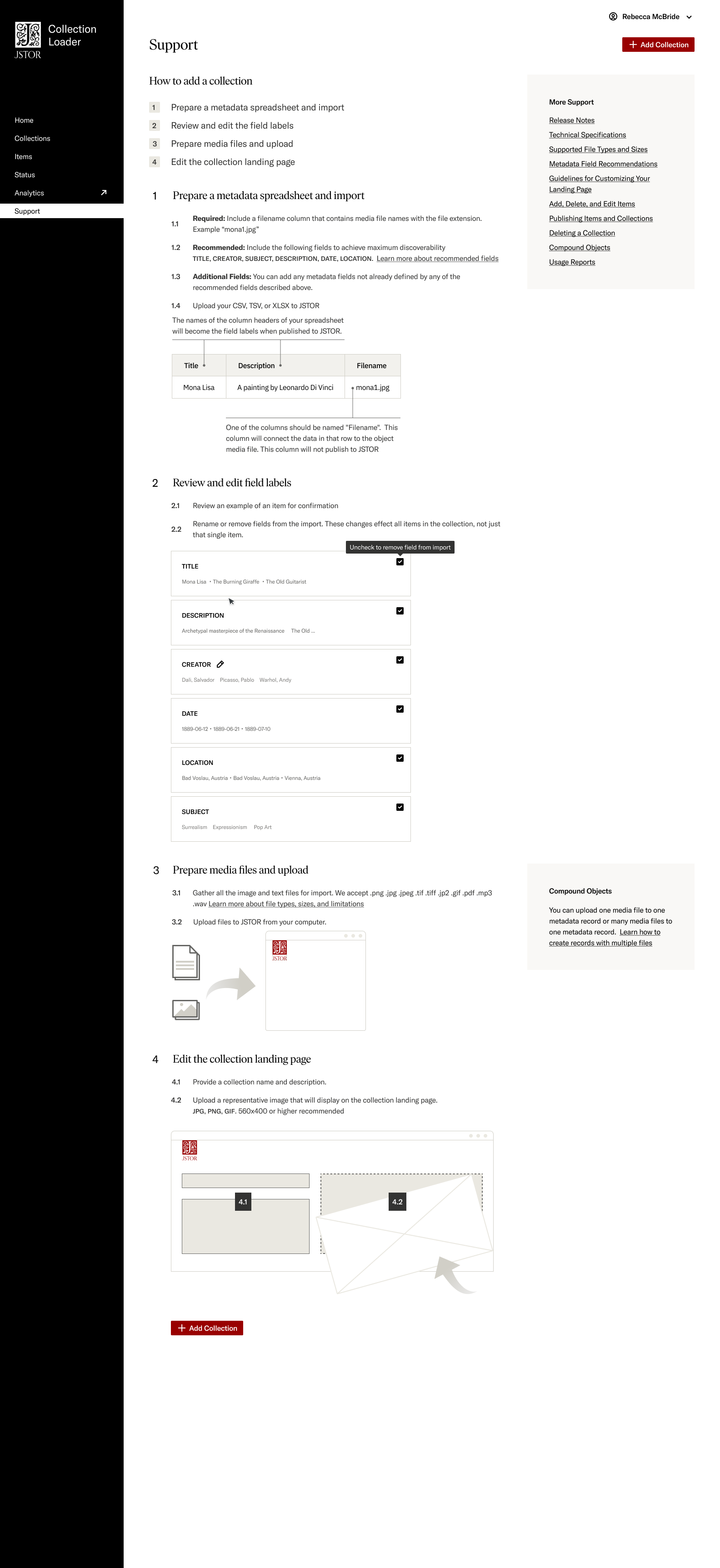
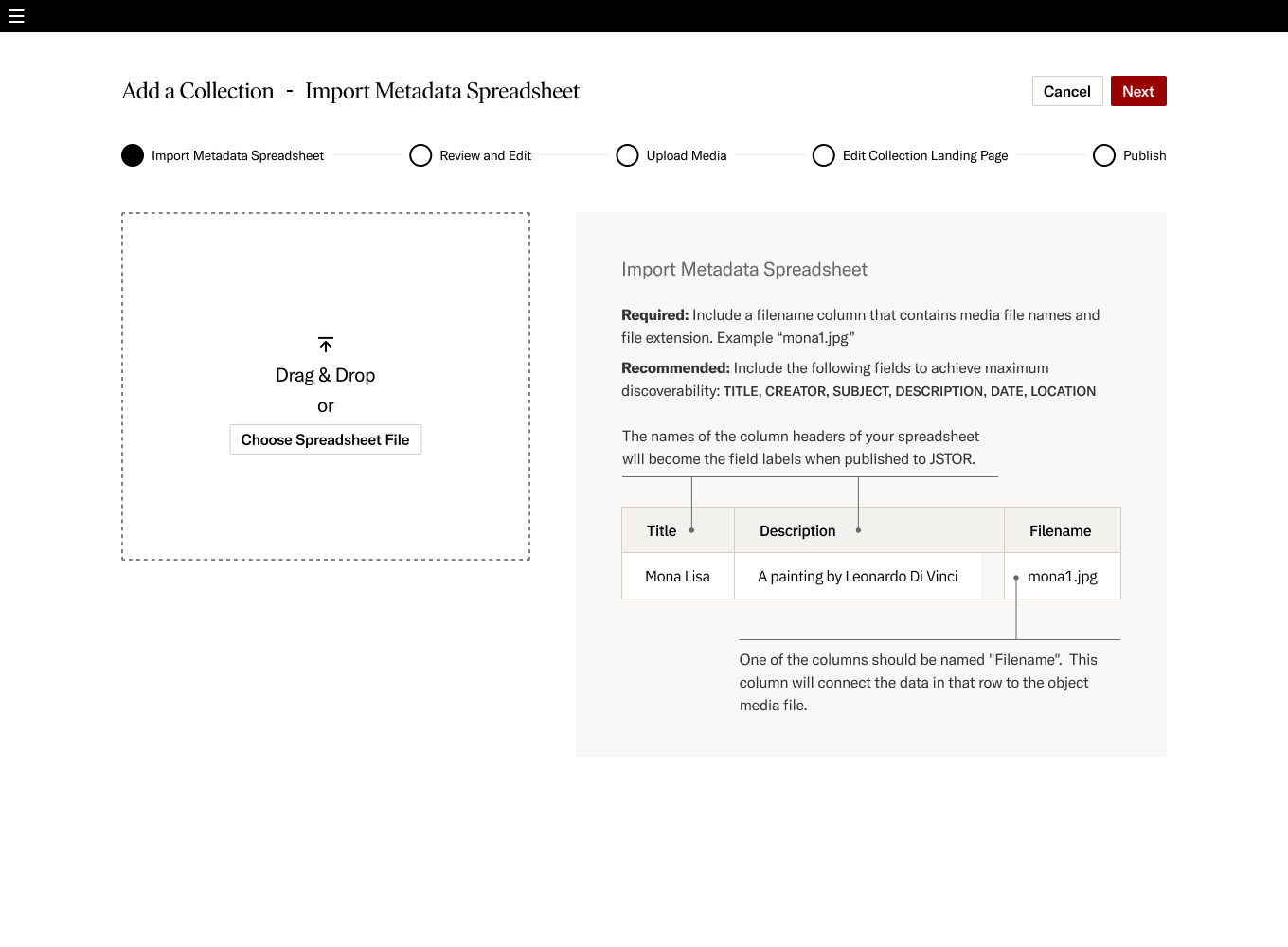
For first-time publishers, we aimed to guide them through the journey of publishing on our platform. The documentation includes diagrams and step-by-step details for each stage of the publishing process. It also contains links to more in-depth support articles on our external help site. I worked closely with the Support team to create an editorial workflow so we could collaborate effectively as the product evolved. This allowed us to keep the publishing documentation up-to-date and provide new users with the assistance they need for a smooth onboarding experience. Additionally, we included contextual assistance at each step so users did not have to exit the flow to understand what to do and gave them the convidence to continue.
Differentiator
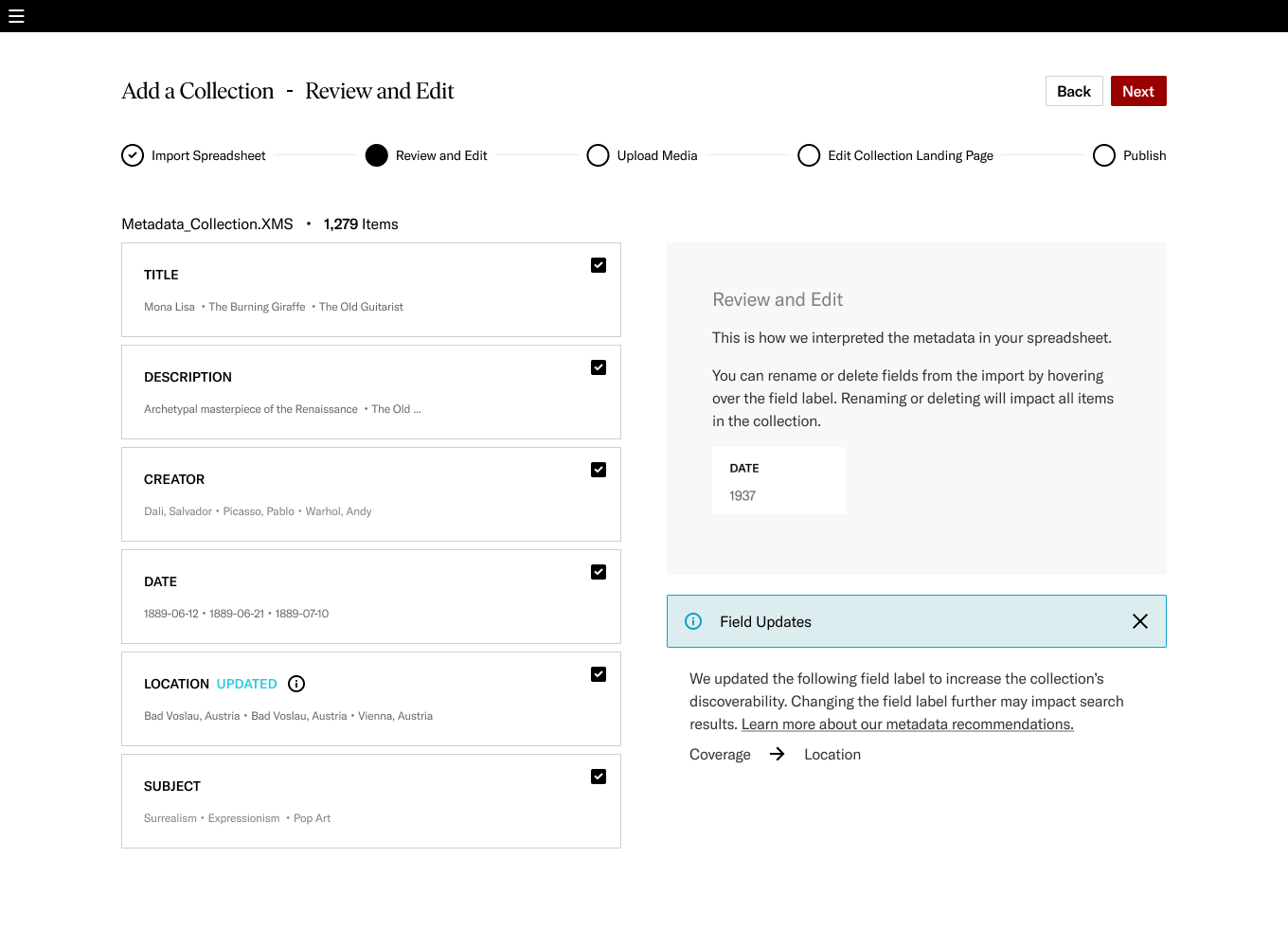
What distinguishes this product from similar ones is that it automatically maps metadata fields from the user's content to corresponding fields in the JSTOR platform. This maximizes discoverability by integrating with JSTOR's search, filter, and sort tools. At the same time, we empower users by allowing them to review the automated mappings, edit them if needed, and opt out if they prefer to manually configure the field mapping. The key differentiation is the combination of automatic metadata mapping for platform integration while still giving users control over how their content is interpreted and presented. This sets us apart by providing both automation for ease of use and autonomy for flexibility - factors that matter greatly to our users.
Visability of System Status
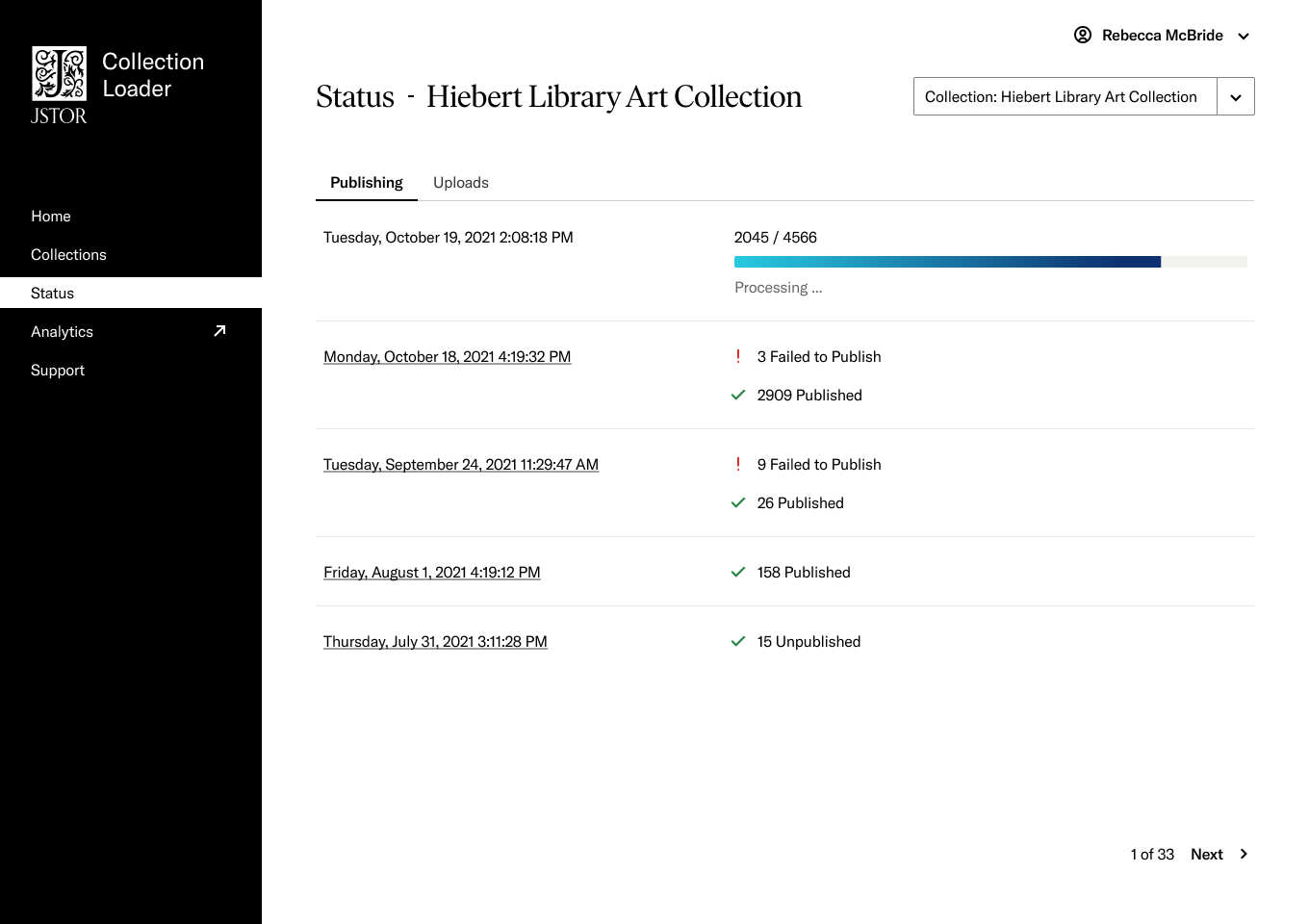
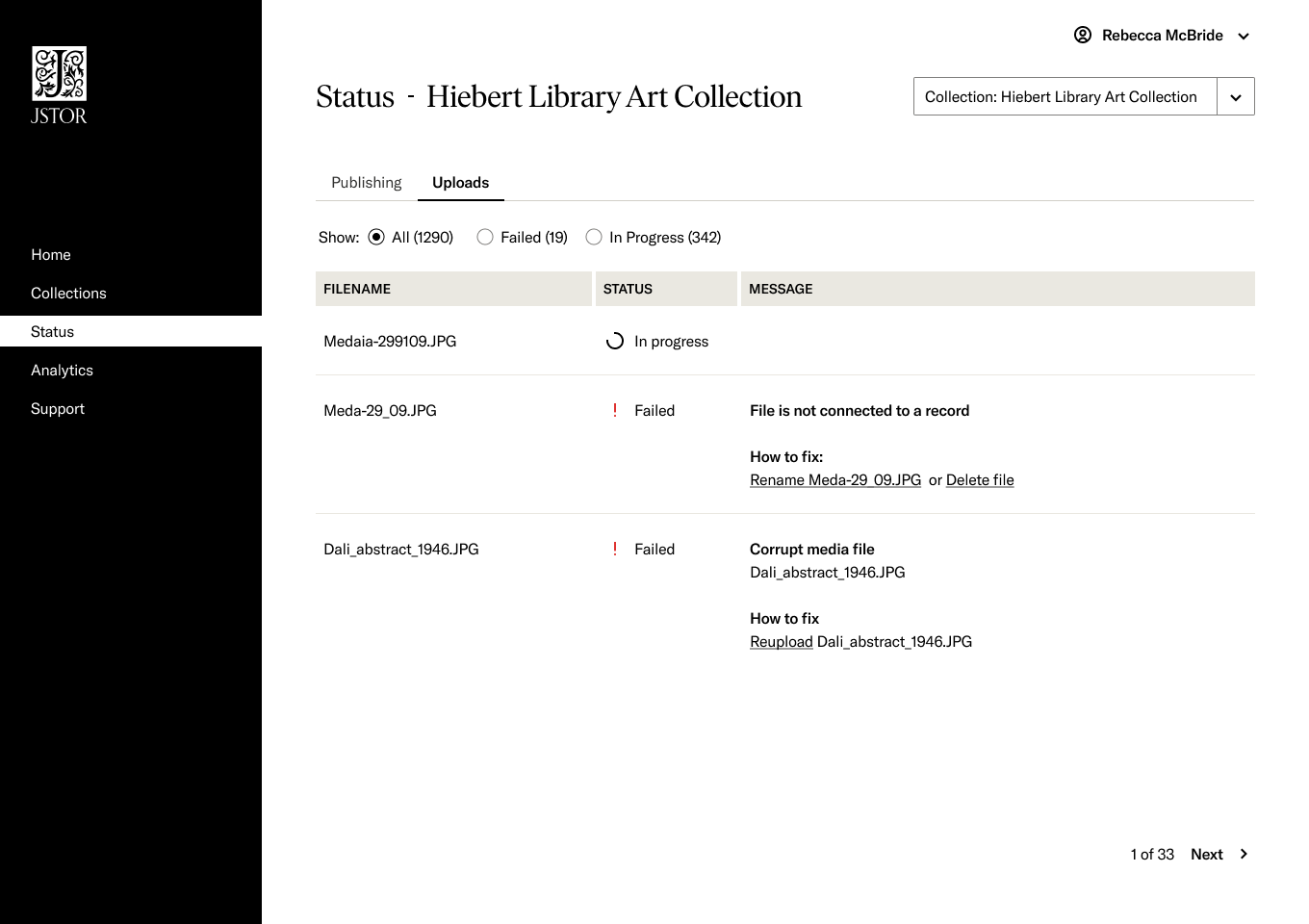
Building trust with our content contributors was crucial so they would feel confident in our ability to be good stewards of their valuable artifacts. To establish trust, we focused on keeping users aware of the ingestion process through timely status updates and easy access to that information. Our goal was to continually inform users where their content is in the workflow, surface any issues quickly, provide ways to fix them, and make status highly visible. By providing transparency into the ingestion process, we aim to demonstrate our capability and care when bringing new materials into the platform. This approach shows contributors we are committed to safeguarding their objects while keeping them looped in each step of the way.
Future Considerations
Collection Loader's future impact on the JSTOR platform
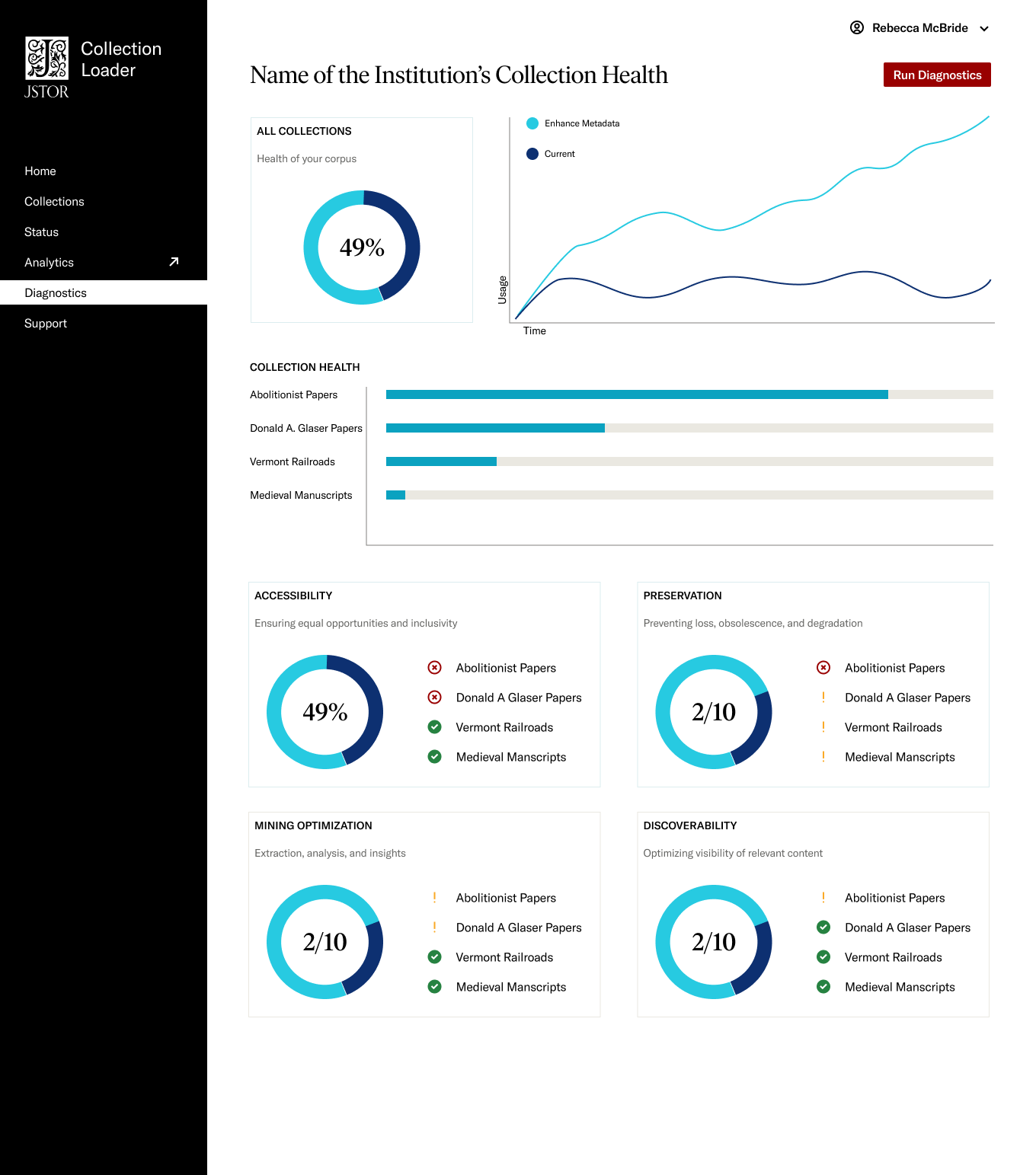
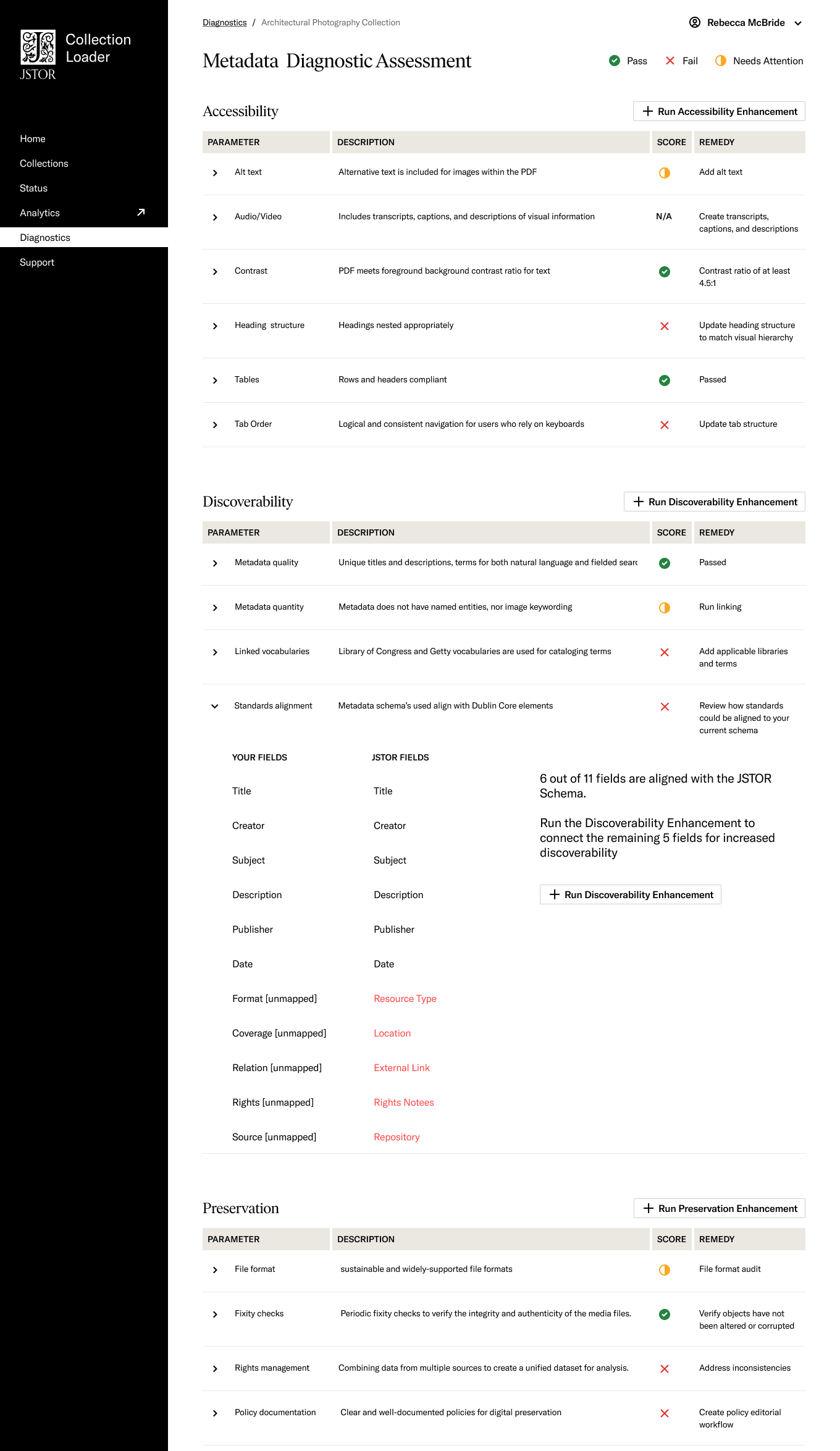
Metadata Diagnostic Tools
Effective metadata management is crucial for large collections of digital assets. With the advent of emerging technologies like large language models (LLMs) and artificial intelligence (AI), metadata can be transformed for discoverability, accessibility, preservation and data mining readiness.
- Accessibility: Ensuring that the collection is accessible to a diverse range of users, including those with disabilities.
- Preservation: Implementing measures to safeguard the long-term integrity and usability of the collection.
- Discoverability: Enhancing the discoverability of the collection to facilitate effective search and retrieval
- Data Mining Readiness: Assessing the collection's readiness for data mining and analytics.
Varying levels of information granularity